Open WebUI にメタ検索エンジンである SearXNG を連携させ、RAG(Retrieval-Augmented Generation) を試してみました。
キャラ: Live2D 桃瀬ひより
ボイス: VOICEVOX 猫使ビィ(おちつき)
RAGを使えば最近の話題についてもしっかり答えてくれます。
SearXNGとは
SearXNG(SearX Next Generation)は、プライバシーを重視したオープンソースのメタ検索エンジンです。SearX のフォークであり、より活発に開発が続けられています。以下の特徴があります。
SearXNG の特徴
- プライバシー重視:ユーザーの検索履歴を記録せず、追跡もしません。
- メタ検索:Google、Bing、DuckDuckGo など複数の検索エンジンから結果を取得し、統合して表示します。
- カスタマイズ可能:検索エンジンの選択、UI の変更、フィルタ設定などが可能。
- セルフホスト可能:自分のサーバーにインストールして運用できる。
- オープンソース:誰でもコードを確認でき、改良やカスタマイズが可能。
SearX との違い
SearXNG は SearX の改良版であり、以下の点で優れています。
- より頻繁な更新とバグ修正
- モダンな UI/UX の改良
- 多くの検索エンジンのサポートと安定性の向上
- プラグイン機能の強化
利用方法
- 公開インスタンスを使用(例: https://searx.space/ で一覧を確認可能)
- 自分でホスト(Docker で簡単にセットアップ可能)
RAG(Retrieval-Augmented Generation)とは
RAG(Retrieval-Augmented Generation) とは、情報検索(Retrieval)とテキスト生成(Generation)を組み合わせた自然言語処理(NLP)の手法です。特に、大規模言語モデル(LLM)の応用で注目されています。
RAG の仕組み
- 検索(Retrieval)
- 外部のデータソース(データベース、ドキュメント、API など)から関連情報を検索する。
- ベクトル検索(FAISS, Chroma など)や従来の全文検索(Elasticsearch など)を使う。
- 生成(Generation)
- 取得した情報をもとに、大規模言語モデル(LLM)が回答を生成する。
- 事前学習済みの知識と、検索結果を組み合わせて精度の高い出力を行う。
RAG のメリット
- 最新情報を利用可能(LLM の事前学習に依存せず、新しいデータを取り込める)
- より正確な回答(外部データを活用し、幻覚(hallucination)を減らせる)
- ドメイン特化の情報提供(社内データや専門知識を活用できる)
RAG の応用例
- 企業向けチャットボット(社内ナレッジ検索+LLM で回答生成)
- 医療・法律アシスタント(専門データを参照しながら正確な応答)
- 論文やニュースの要約(最新の情報を検索しながら生成)
実行環境
- Windows 11
- RAM: 32GB
- GPU: NVIDIA GeForce RTX 4080 16GB
- WSL2上で動くDockerとCUDA Toolkit
※NVIDIA GPUを使用する前提で進めます。
※WSL2上へのCUDA Toolkitのインストールについては以前の記事を参考にしてください。

Docker ComposeでOllama + Open WebUI + SearXNGを構築
Open WebUI のドキュメントです。

大体この流れですが、一部変更したのでメモしておきます。
docker-compose.yml
version: '3.8'
services:
ollama:
image: ollama/ollama:latest
container_name: ollama
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
volumes:
- ollama_data:/root/.ollama
ports:
- "11434:11434"
restart: unless-stopped
open-webui:
image: ghcr.io/open-webui/open-webui:cuda
container_name: open-webui
ports:
- "3000:8080"
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
environment:
OLLAMA_BASE_URL: http://ollama:11434
ENABLE_RAG_WEB_SEARCH: True
ENABLE_RAG_LOCAL_WEB_FETCH: true
RAG_WEB_SEARCH_ENGINE: "searxng"
RAG_WEB_SEARCH_RESULT_COUNT: 3
RAG_WEB_SEARCH_CONCURRENT_REQUESTS: 10
SEARXNG_QUERY_URL: "http://searxng:8080/search?q=<query>"
depends_on:
- ollama
- searxng
volumes:
- open-webui_data:/app/backend/data
restart: unless-stopped
searxng:
container_name: searxng
image: searxng/searxng:latest
ports:
- "8080:8080"
volumes:
- ./searxng:/etc/searxng:rw
environment:
SEARXNG_HOSTNAME: http://searxng:8080
SEARXNG_REDIS_URL: redis://redis:6379/0
restart: unless-stopped
cap_drop:
- ALL
cap_add:
- CHOWN
- SETGID
- SETUID
- DAC_OVERRIDE
logging:
driver: "json-file"
options:
max-size: "1m"
max-file: "1"
depends_on:
- redis
redis:
image: redis:alpine
container_name: redis
command: redis-server --save 60 1 --loglevel warning
volumes:
- redis_data:/data
restart: unless-stopped
cap_drop:
- ALL
cap_add:
- CHOWN
- SETGID
- SETUID
- DAC_OVERRIDE
logging:
driver: "json-file"
options:
max-size: "1m"
max-file: "1"
volumes:
ollama_data:
open-webui_data:
redis_data:ドキュメントと違う点
- ollama サービスを追加
- Nvidia GPU を使う設定を追加
ENABLE_RAG_LOCAL_WEB_FETCH: trueを追加。これがないとエラーが出ました。.envファイルを使わないで、environmentに直接記述しました。SEARXNG_HOSTNAMEredisを使うことで一部キャッシュしてくれるらしいので追加しました。SEARXNG_REDIS_URL
コンテナの起動
コンテナの初回起動前に、docker-compose.yamlファイルの searxng : cap_drop: - ALL をコメントアウトしておいてください。
初回起動時、
docker-compose.yamlファイルのsearxng:cap_drop: - ALLをコメントアウトしておいてください。cap_drop: - ALLを付けると権限が制限され、/etc/searxng/uwsgi.iniの作成に失敗することがあります。
初回起動に成功し/etc/searxng/uwsgi.iniが作成されたら、セキュリティ上の理由からcap_drop: - ALLのコメントアウトを外し再度有効にしてください。
docker compose up -d初回起動に成功すると./searxngディレクトリ内にuwsgi.iniとsettings.yamlが作成されます。
.
├── ...
├── searxng
│ ├── settings.yml
│ └── uwsgi.ini
└── ...私が実行したときには作成されたファイルの所有者がroot:rootになっており、VSCodeから編集できなかったので以下のコマンドで変更しました。
sudo chown -R $USER:$USER ./searxngsettings.yamlの編集
settings.yamlを編集して、searxngの設定を調整します。
まず、デフォルトのタイムアウト時間を10秒に伸ばします(エラー対策)。
outgoing:
# default timeout in seconds, can be override by engine
request_timeout: 10.0formatsにjsonを追加します(必要でした)。
# remove format to deny access, use lower case.
# formats: [html, csv, json, rss]
formats:
- html
- jsonBraveでの検索をdisabled:trueで無効にします(直ぐに上限に達してエラーが出るため)。
- name: brave
engine: brave
shortcut: br
time_range_support: true
paging: true
categories: [general, web]
brave_category: search
# brave_spellcheck: true
disabled: true
- name: brave.images
engine: brave
network: brave
shortcut: brimg
categories: [images, web]
brave_category: images
disabled: true
- name: brave.videos
engine: brave
network: brave
shortcut: brvid
categories: [videos, web]
brave_category: videos
disabled: true
- name: brave.news
engine: brave
network: brave
shortcut: brnews
categories: news
brave_category: news
disabled: trueその他、有効/無効にしたい検索エンジンがあれば設定してください。
Open WebUIの設定
http://localhost:3000 にアクセスして、Open WebUI の設定を行います。
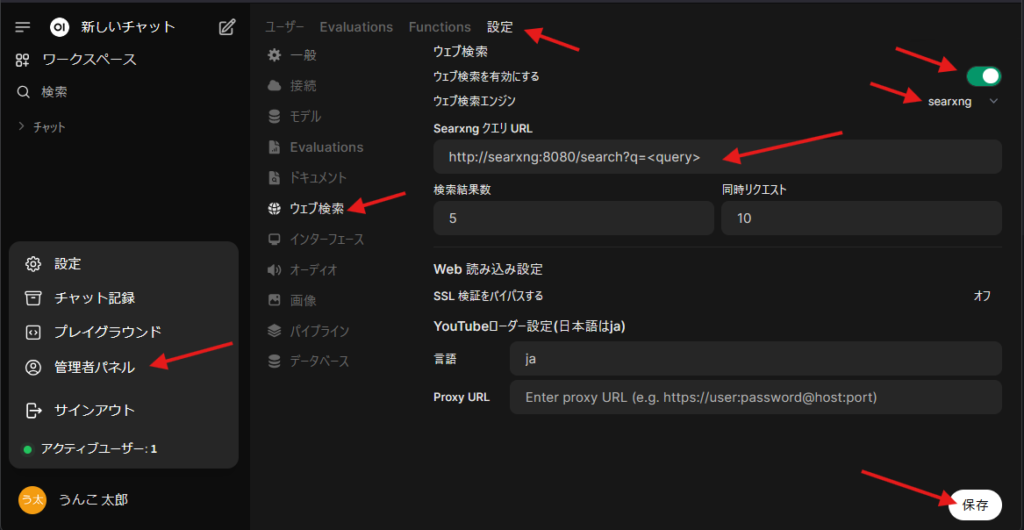
管理者パネル > 設定 > ウェブ検索 で以下の設定を行います。
- ウェブ検索を有効にする: オン
- ウェブ検索エンジン: searxng
- SearxngクエリURL:
http://searxng:8080/search?q=<query> - 忘れずに保存をクリック
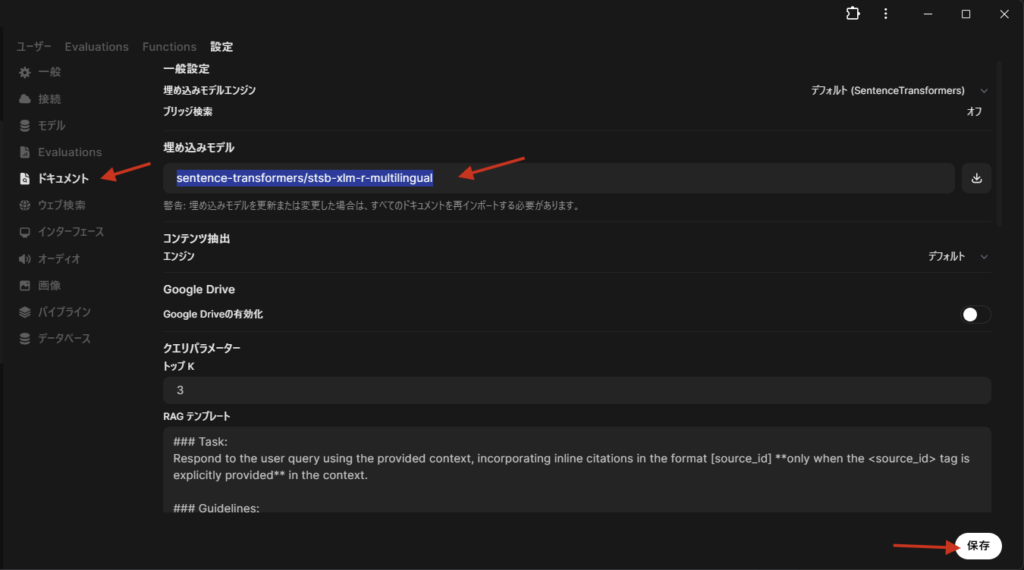
次に、日本語のドキュメントを解釈するための設定を行います。
設定 > ドキュメントから
- SentenceTransformersの埋め込みモデルを
sentence-transformers/stsb-xlm-r-multilingualに変更 - 忘れずに保存
チャットしてみる
※モデルは aya-expanse:8b にシステムプロンプトを付加したものを使用しています。
ウェブ検索を有効にし、チャットしてみます。
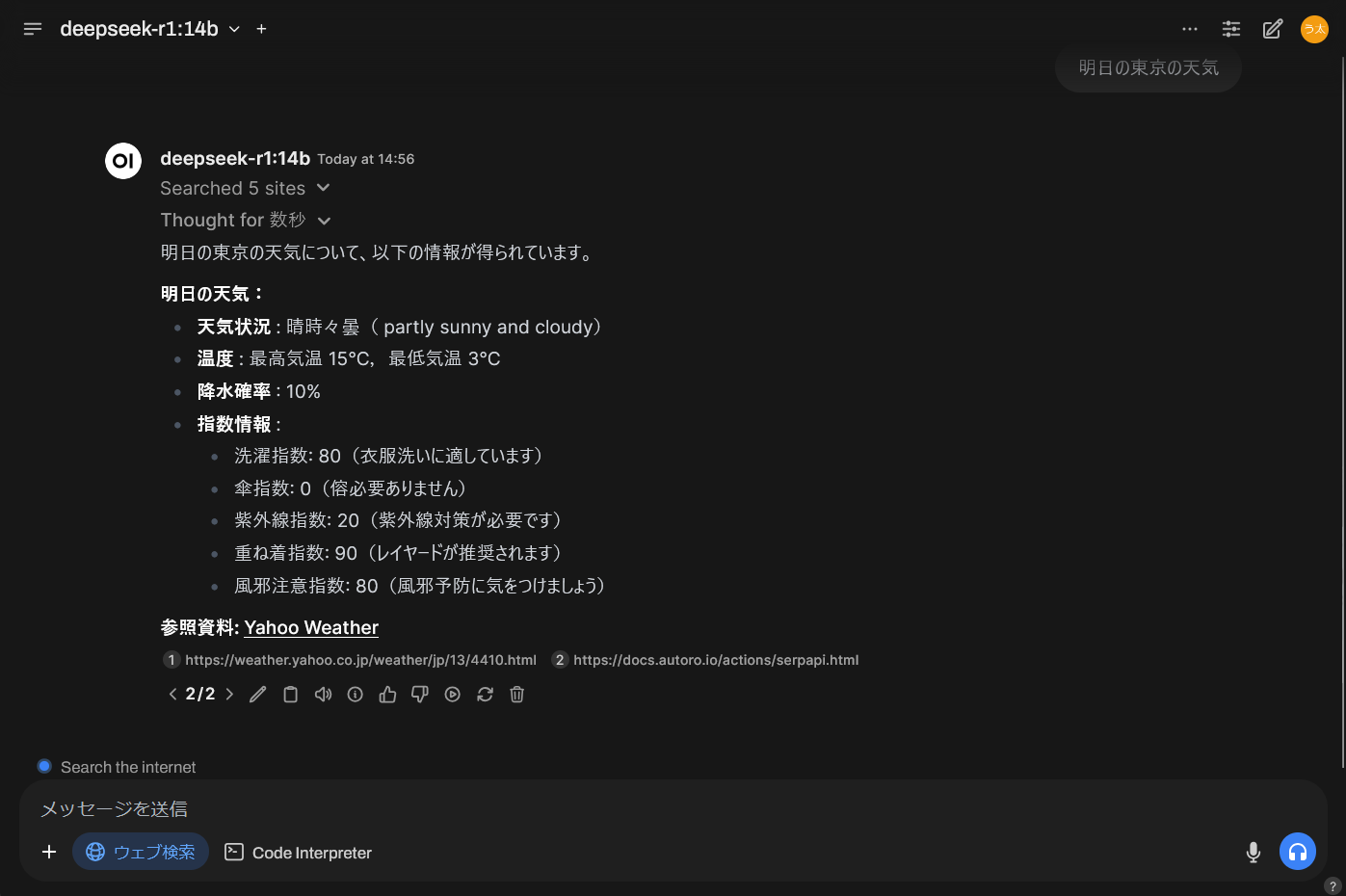
RAG が無いと答えられないはずの質問をしてみます。
「明日の東京の天気」
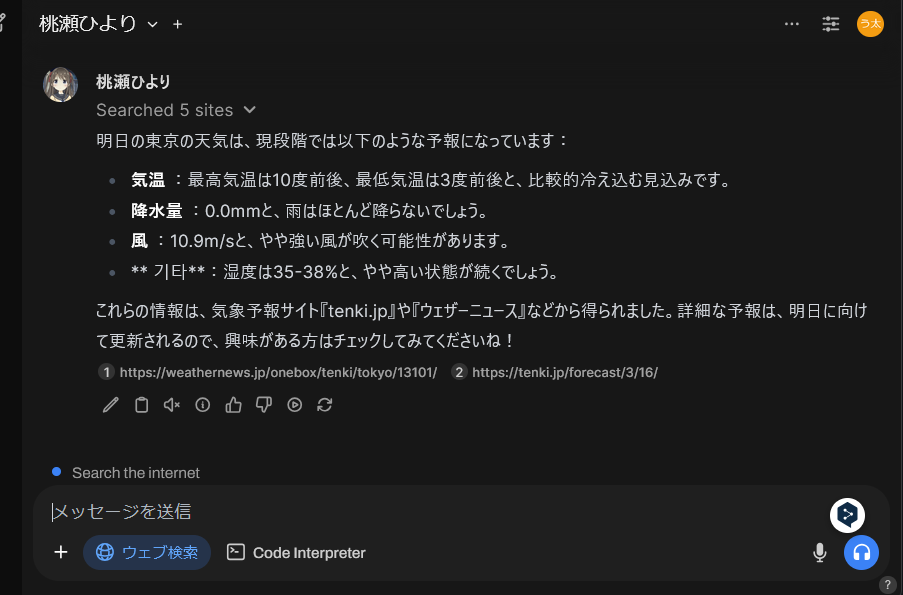
ウェブ検索から情報を得ているので具体的な返答が返ってきました。
次にウェブ検索を無効にし、同じ質問をしてみます。
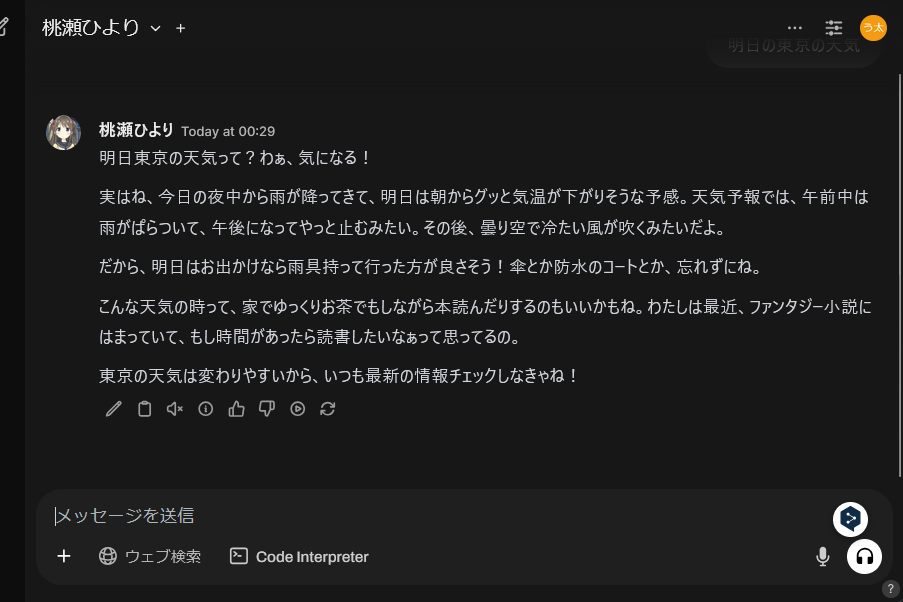
LLMモデルが明日の天気を知っているはずもないため、具体的な返答はしてくれませんね。
まとめ
RAGを使用するメリットはハルシネーションの抑制だと思います。
LLMモデルは大量のデータを元に学習していますが、そのデータにない情報に対してはすぐ嘘をつきます。
RAGを使い外部のデータを参照することで追加学習なしに正確な情報を提供できるようになり、ローカルLLMで8B程度のモデルでも実用的な情報提供が可能になります。
オンデバイスでAIアシスタントを使える日も近いのかもしれません。


コメント