
いつの間にかローカル動画生成が進化していました。
今回はComfyUIのインストールから、HunyuanVideoを使ってImage2Videoを実行するまでを書いていきます。
はじめに
実行環境
- Windows 11
- NVIDIA RTX 4080 16GB
使うもの
Git for Windows

7zip

PowerShell7
必要ではありませんが、cmd より使いやすいのでおすすめです。

CUDA Toolkit
現時点(2025/02)で最新は12.8。

12.4以上が必要です。
インストール済みの方も、12.4以上か確認してください。nvcc -V で確認できます。
> nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2025 NVIDIA Corporation
Built on Wed_Jan_15_19:38:46_Pacific_Standard_Time_2025
Cuda compilation tools, release 12.8, V12.8.61
Build cuda_12.8.r12.8/compiler.35404655_0Visual Studio
wheel のビルドに必要です。

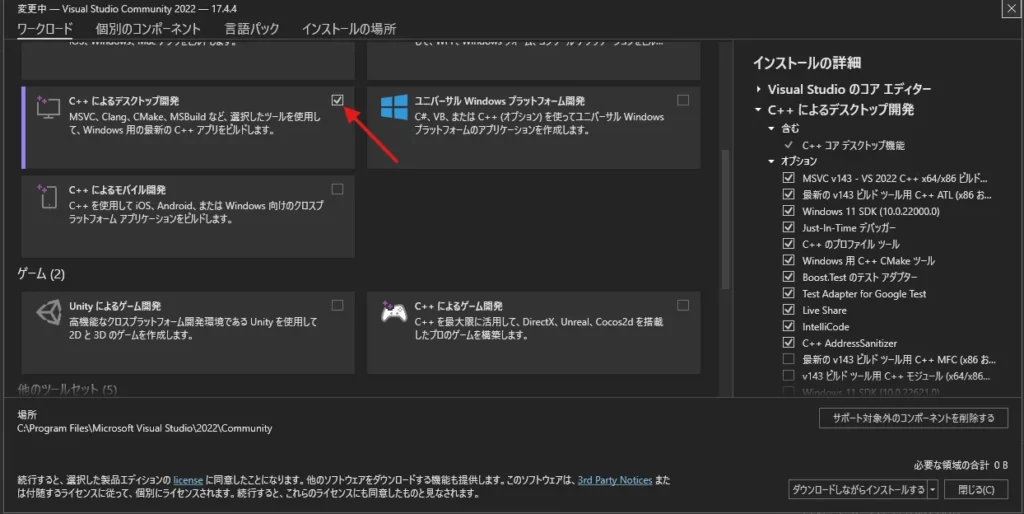
Visual Studio Community のインストーラーをダウンロードし、実行してください。
必要なものは「C++ によるデスクトップ開発」です。
ComfyUIのインストール
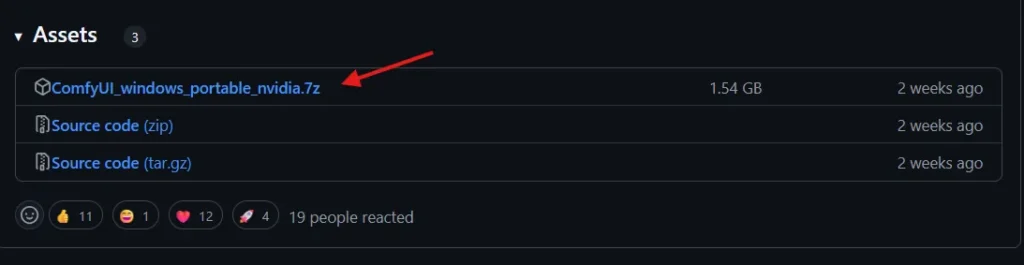
ComfyUIのダウンロード

ポータブル版をダウンロードして解凍します。
ComfyUI-Managerのインストール
解凍先の ComfyUI_windows_portable/ComfyUI/custom_nodes をターミナルで開いたら以下のコマンドを実行し、ComfyUI-Managerをクローンします。
git clone https://github.com/ltdrdata/ComfyUI-Manager comfyui-managerComfyUI-Managerのインストールの確認
ComfyUI_windows_portable/run_nvidia_gpu.bat を実行すると、http://127.0.0.1:8188/ がブラウザで開かれます。
右上にComfyUI-Managerのアイコンが表示されていればOK。
必要パッケージのインストール
SageAttention2 をインストールする必要があります。
必要要件は以下のとおりです。
- python>=3.9
- torch>=2.3.0
- CUDA>=12.4
- triton>=3.0.0
まずバージョン確認を行います。
Pythonのバージョン確認 python.exe -V
> ..\python_embeded\python.exe -V
Python 3.12.8CUDAのバージョン確認 nvcc -V
> nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2025 NVIDIA Corporation
Built on Wed_Jan_15_19:38:46_Pacific_Standard_Time_2025
Cuda compilation tools, release 12.8, V12.8.61
Build cuda_12.8.r12.8/compiler.35404655_0torchと諸々のインストール
ComfyUI_windows_portable/update フォルダに移動し、以下のコマンドを実行して必要パッケージをインストールします。
..\python_embeded\python.exe -s -m pip install "accelerate >= 1.1.1"
..\python_embeded\python.exe -s -m pip install "diffusers >= 0.31.0"
..\python_embeded\python.exe -s -m pip install "transformers >= 4.39.3"
..\python_embeded\python.exe -s -m pip install ninja
..\python_embeded\python.exe -s -m pip install --upgrade torch torchvision torchaudio xformers==0.0.29.post3 --index-url https://download.pytorch.org/whl/cu124tritonのインストール
tritonパッケージのインストール
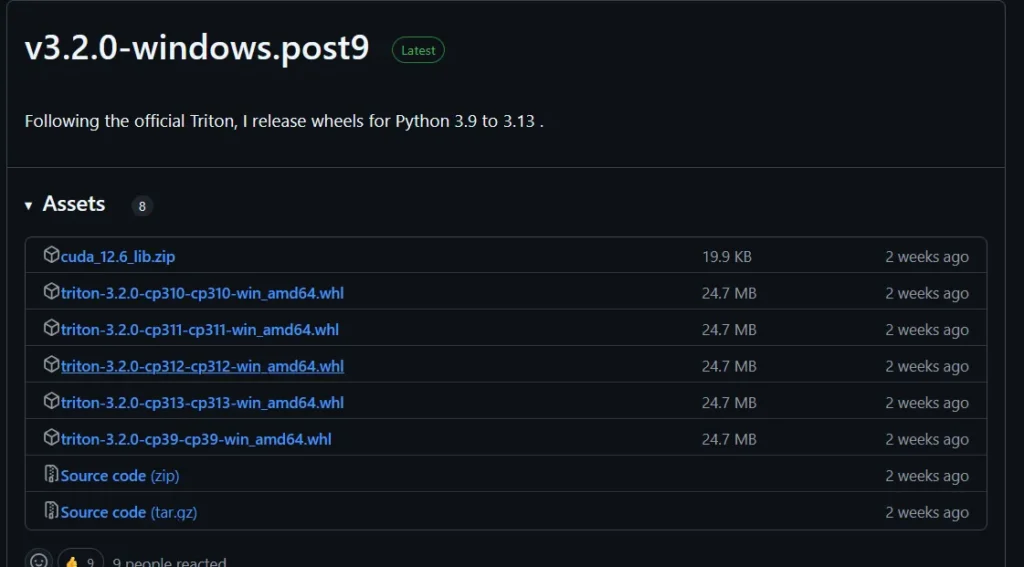
woct0rdho/triton-windows から最新のリリースをダウンロードします。

先ほど確認したPythonのバージョンに合わせてダウンロードしてください。私の場合は Python 3.12.8 だったので、triton-3.2.0-cp312-cp312-win_amd64.whl をダウンロードしました。
ダウンロードした .whl ファイルを ComfyUI_windows_portable/update に置き、以下のコマンドを実行しインストールます。※バージョン部分は適宜変更
..\python_embeded\python.exe -s -m pip install triton-3.2.0-cp312-cp312-win_amd64.whlincludeとlibsの配置
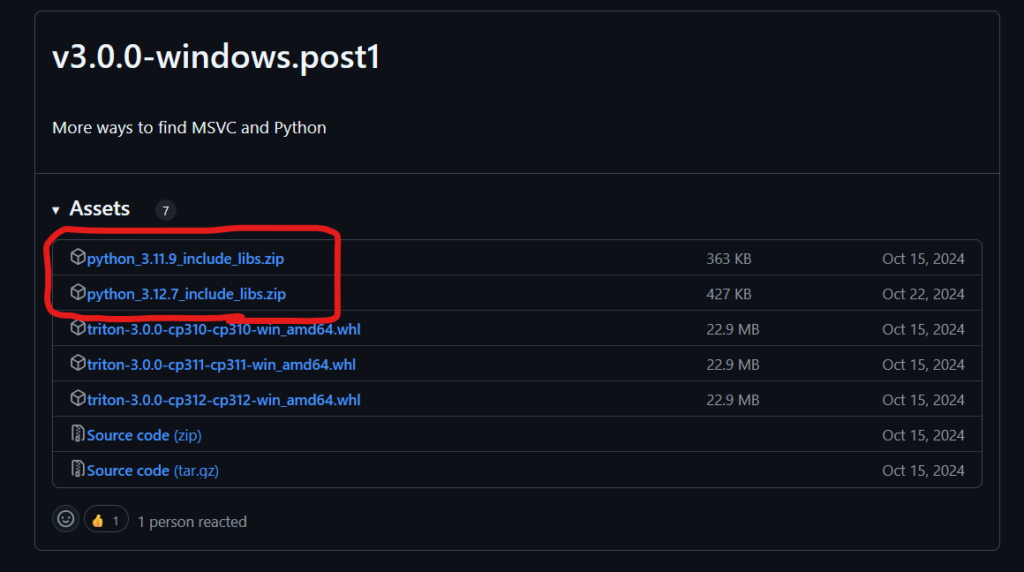
woct0rdho/triton-windows から python_3.12.7_include_libs.zip をダウンロードします。
(Python3.11系の場合は python_3.11.9_include_libs.zip)

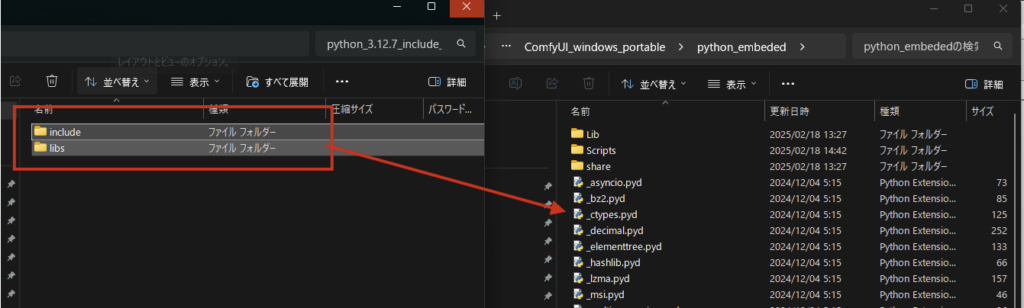
ダウンロードしたファイルを解凍し、include と libs を ComfyUI_windows_portable/python_embeded にコピーします。
SageAttentionのインストール
Comfyi-windows-portable フォルダに移動し、以下のコマンドを実行しインストールします。
git clone https://github.com/thu-ml/SageAttention
cd SageAttention
..\python_embeded\python.exe -m pip install .bitsandbytesのインストール
4bit/8bit量子化を行うために必要です。
ComfyUI_windows_portable/update フォルダに移動し、以下のコマンドを実行します。
..\python_embeded\python.exe -s -m pip install bitsandbytes>=0.45.1テスト
ここまでのインストールがうまくいっているか確認します。
ComfyUI_windows_portable/test.py を作成し、次のコードを記述してください。
import torch
import triton
import triton.language as tl
@triton.jit
def add_kernel(x_ptr, y_ptr, output_ptr, n_elements, BLOCK_SIZE: tl.constexpr):
pid = tl.program_id(axis=0)
block_start = pid * BLOCK_SIZE
offsets = block_start + tl.arange(0, BLOCK_SIZE)
mask = offsets < n_elements
x = tl.load(x_ptr + offsets, mask=mask)
y = tl.load(y_ptr + offsets, mask=mask)
output = x + y
tl.store(output_ptr + offsets, output, mask=mask)
def add(x: torch.Tensor, y: torch.Tensor):
output = torch.empty_like(x)
n_elements = output.numel()
grid = lambda meta: (triton.cdiv(n_elements, meta["BLOCK_SIZE"]),)
add_kernel[grid](x, y, output, n_elements, BLOCK_SIZE=1024)
return output
a = torch.rand(3, device="cuda")
b = a + a
b_compiled = add(a, a)
print(b_compiled - b)
print("If you see tensor([0., 0., 0.], device='cuda:0'), then it works")実行
.\python_embeded\python.exe .\test.pytensor([0., 0., 0.], device='cuda:0') と表示されれば大丈夫です。
もし、ImportError: DLL load failed while importing cuda_utils: 指定されたモジュールが見つかりません。 と表示された場合は、C:\Users\ユーザー名\.triton フォルダを削除し、再度実行してみてください。
学習済みモデルのダウンロード
VAEのダウンロード
- hunyuan_video_vae_bf16.safetensors

ファイルは下記のフォルダ内に置きます( hyvid フォルダがない場合は作成)。
ComfyUI_windows_portable\ComfyUI\models\vae\hyvid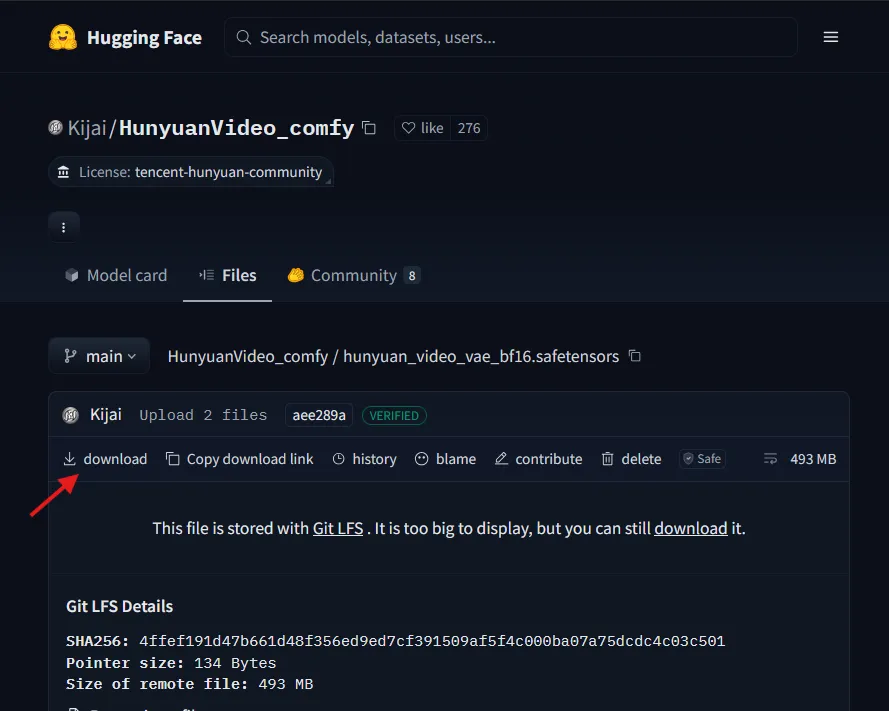
Hunyuan Video model のダウンロード
- hunyuan_video_720_cfgdistill_fp8_e4m3fn.safetensors
- hunyuan_video_FastVideo_720_fp8_e4m3fn.safetensors
下記のフォルダ内に置きます。
ComfyUI_windows_portable\ComfyUI\models\diffusion_models\hyvidLeapfusion Hunyuan Image-to-Video Lora のダウンロード
今回はImage2Videoを試したいのでLeapfusion Hunyuan Image-to-Video Lora weightsをダウンロードします。
- img2vid544p.safetensors

下記のフォルダ内に置きます。
ComfyUI_windows_portable\ComfyUI\models\loras\hyvid実行
必要ノードのインストール
ComfyUI_windows_portable/run_nvidia_gpu.bat を実行し、ComfyUIの画面を開いておいてください。
Civitai にある、下記ワークフローを使います。

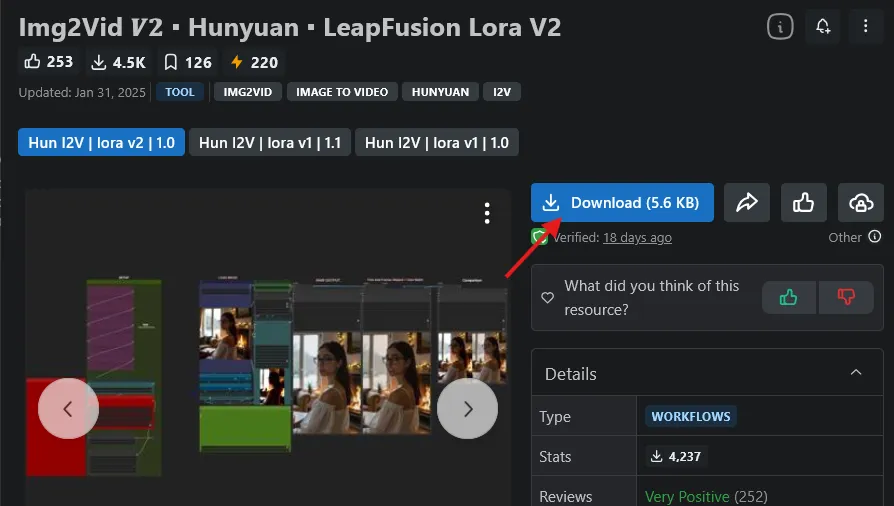
zipファイルを解凍し、Hunyuan-Img2Vid-LeapFusion v2 1.0.json をComfyUIのブラウザ画面にドラッグ&ドロップします。
必要なカスタムノードがインストールされていないので、警告が出ます。
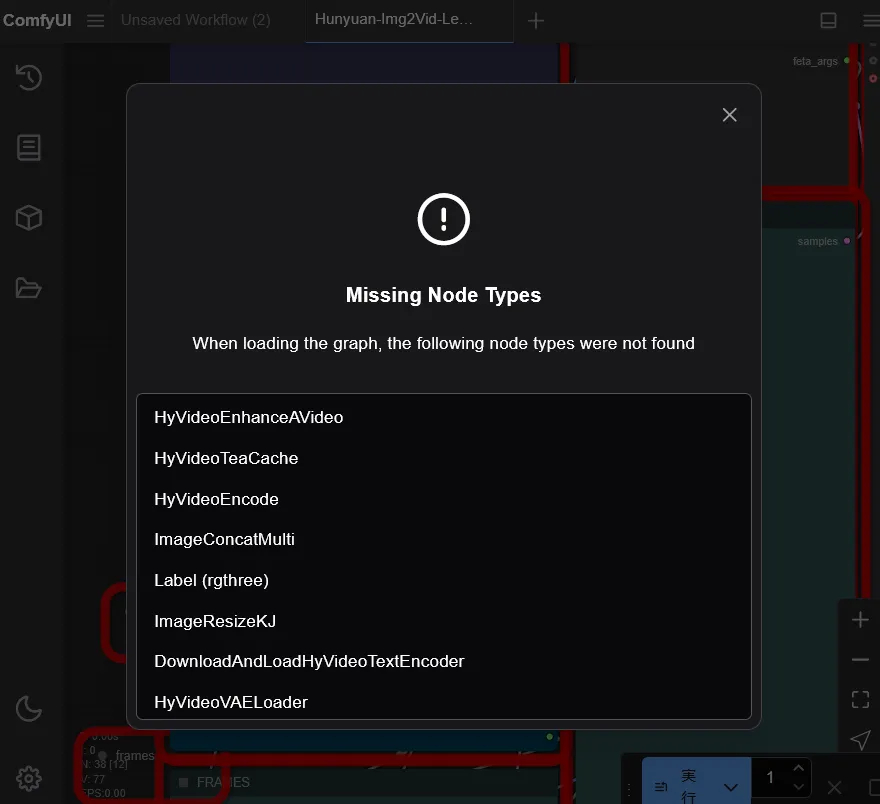
右上のComfyUI-Managerのアイコンをクリックし、「Install Missing Custom Nodes」をクリックします。
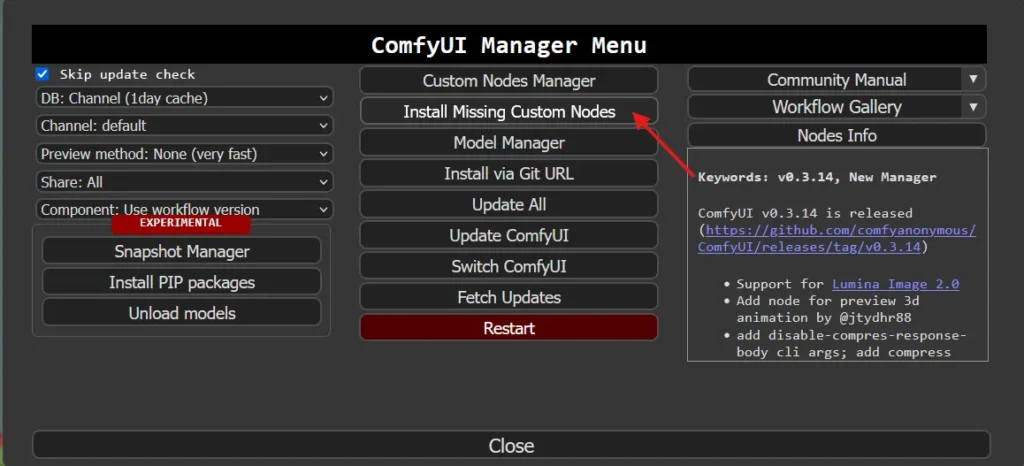
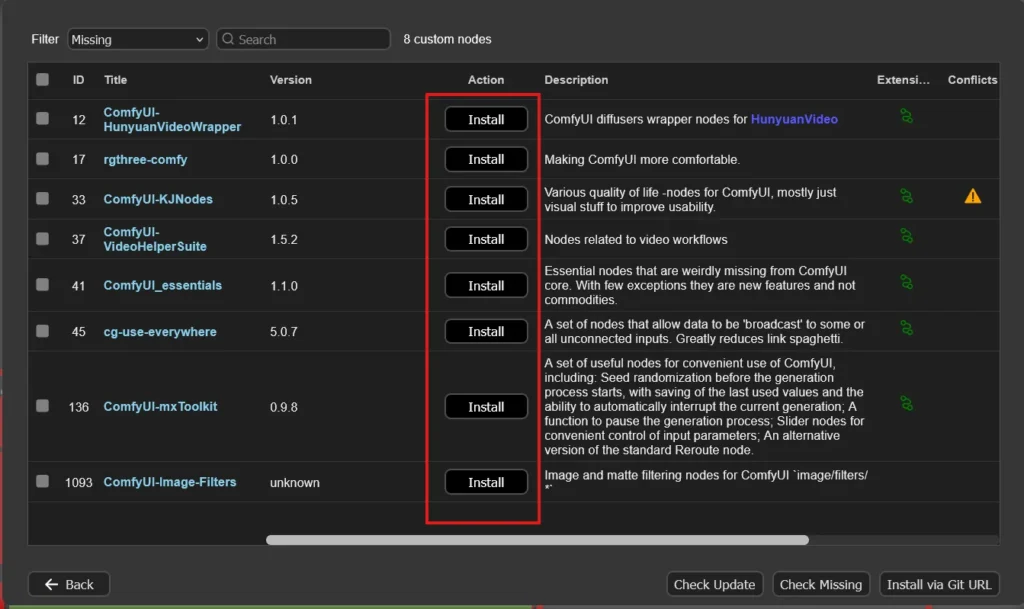
「Install」をクリックし、すべてインストールします。※バージョンはlatestを選択しました。
Comfy UI の再起動を促されるので、左下の「Restart」をクリックして再起動します。
再起動が終わり、ブラウザ画面がリフレッシュされるとエラーが消えていると思います。
各ノードの設定
生成前に各ノードの設定を行います。
設定は一例なので参考程度に。
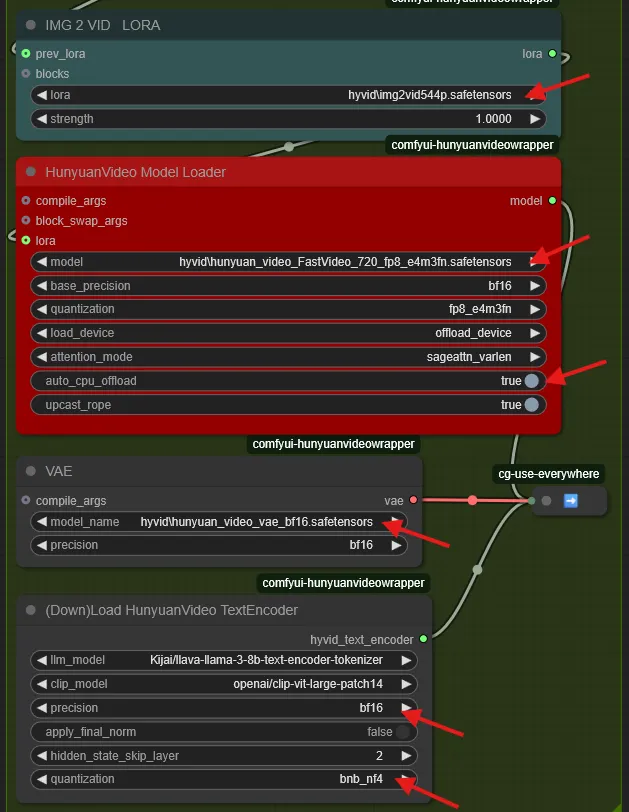
- IMG2VID LORA ノード
- lora:
hyvid/img2vid544p.safetensors
- lora:
- HunyuanVideo Model Loader
- model:
hyvid/hunyuan_video_720_FastVideo_fp8_e4m3fn.safetensors - auto_cpu_offload:
True
- model:
- VAE
- model_name:
hyvid/hunyuan_video_vae_bf16.safetensors
- model_name:
- (Down)Load HunyuanVideo TextEncoder
- precision:
bf16 - quantization:
bnb_nf4
- precision:
- HunyuanVideo Sampler
- steps:
6 - embedded_guidance_scale:
6 - flow_shift:
20
- steps:
- HunyuanVideo Enhance A Video
- weight:
8.00 - start_percent:
0.0 - end_percent:
0.8
- weight:
- HunyuanVideo Decode
- spatial_tile_sample_min_size:
160※VRAMに合わせて調整
- spatial_tile_sample_min_size:
auto_cpu_offload でVRAM使用量を抑えることができます。
upcast_ropeを無効にすることでもVRAM使用量を抑えることができるらしいですが、私には実感できませんでした。
TextEncoderは bnb_nf4 で問題なかったので選びました。
専用GPUメモリに収まらないと途端に遅くなります。フレーム数や画像サイズなど、VRAM容量に合わせて調整してください。
初回実行時、llm_modelとclip_modelのダウンロードが始まるため少し時間がかかります。
生成
スマホで撮影した白鳥の画像を入力してみます。

544×960で65フレームの動画の生成に計1分30秒ほどかかりました。
生成動画:
544×960の97フレームで2分程度かかりました。この辺がVRAM16GBで快適に動かせる限界でした。
生成動画:
まとめ
ComfyUIとHunyuanVideoを使ってImage2Videoを試してみました。
ローカル動画生成は制限や検閲が無いことがメリットだと思います。
Cvitai などでhunyuan関連のLoraも多数公開されてきているので、ぜひ良いものを探して試してみてください。



コメント