
kijai氏のComfyUI-HunyuanVideoWrapperでIP2Vを実行し、画像に似た雰囲気の動画を生成します。
概要
IP2V
IP2V(Image Prompt to Video)は、画像をプロンプトとして利用し、そのスタイルやコンセプトを抽出して動画を生成する技術です。
I2V(Image to Video)との違いは以下の通りです。
- IP2V(Image Prompt to Video): この手法では、入力画像をプロンプトとして使用し、その画像の内容やスタイルを理解して、それに基づいた動画を生成します。具体的には、画像を視覚と言語の両方を理解するモデル(VLM: Vision-Language Model)に入力し、画像の特徴を抽出して動画生成に活用します。これにより、画像のスタイルやコンセプトを反映した動画を生成することが可能となります。
- I2V(Image to Video): 一方、I2Vは、特定の画像を直接的に動画に変換する技術です。例えば、静止画を連続したフレームに展開し、動画として再生することで、画像から動画を生成します。この手法では、入力画像の内容を保持しつつ、時間的な変化を持たせた動画を作成することが主な目的となります。
ざっくり言うと
- IP2V: 画像に似た雰囲気の動画を生成したいときに使う
- I2V: 画像を動かしたいときに使う
実行環境
- OS: Windows 11
- GPU: NVIDIA GeForce RTX 4080 16GB
- ComfyUI_portable
ComfyUIやtritonその他インストールについては以前の記事を参考にしてください。

HunyuanVideo モデル


ワークフロー
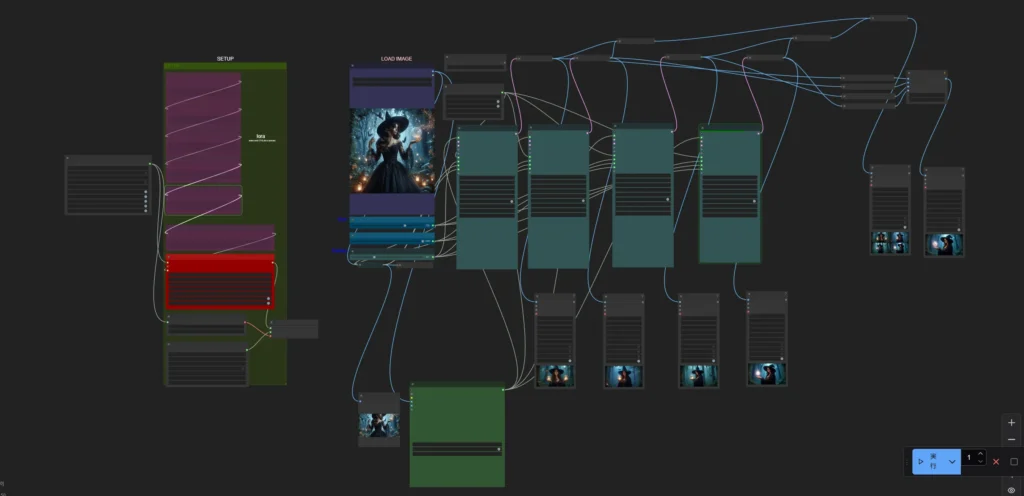
入力画像
生成した画像です。

プロンプト
FPS-24, In an enchanting forest, a witch of <image> plays with a magical bird. She wears a flowing black lace dress and a wide-brimmed witch hat, with long wavy hair gently swaying in the breeze. As she lifts her hand, a glowing magical orb appears, releasing sparkling light particles that transform into a luminous bird. The ethereal bird flutters gracefully around her, perching on her fingertip and dancing through the air. Soft lantern lights illuminate the mystical woods, while black butterflies and bats hover nearby. In the misty, moonlit night, the witch smiles gently, immersed in this mesmerizing moment of magic and serenity.
8K photorealistic rendering.
IP2Vでの生成方法
HunyuanVideo TextImageEncode(IP2V) ノード
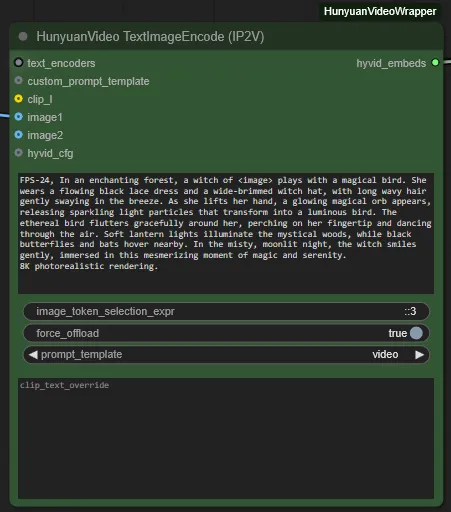
HunyuanVideo TextImageEncode(IP2V) ノードに画像を接続することで、画像をプロンプトとして使用できます。
プロンプトには <image> というタグを含めておきましょう。
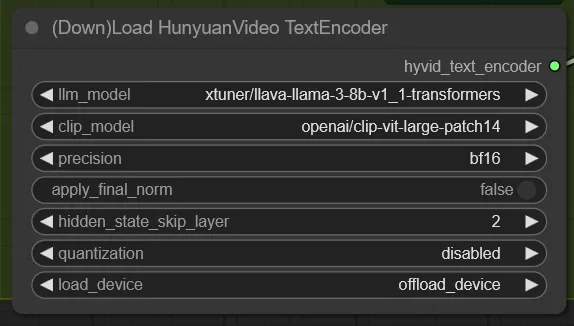
TextEncoderのllm_modelには xtuner/llava-llama-3-8b-v1_1-transformers を指定します。
また、quantizationは disabled にしないとダメでした。
補足:エラーへの対処
実行時、HunyuanVideo TextImageEncode(IP2V) ノードでエラーが発生しました。
File "ComfyUI_windows_portable\python_embeded\Lib\site-packages\transformers\models\llava\processing_llava.py", line 160, in __call__
num_image_tokens = (height // self.patch_size) * (
~~~~~~~^^~~~~~~~~~~~~~~~~
TypeError: unsupported operand type(s) for //: 'int' and 'NoneType'transformers==4.47.0 をバージョン指定でインストールすることで解決しました。
.\python_embeded\python.exe -s -m pip install transformers==4.47.0生成結果
1回のワークフローで
- 4つの動画を生成
- フレーム補間で72FPS(3倍)に変換
- 動画を結合して1つの動画にする
という処理を行いました。
VRAM16GBで動かせるように設定を調整しています。
あと、生成時間に関してはGPUを70%制限していることに留意してください。
HunyuanVideoモデル
- model: hunyuan_video_720_cfgdistill_fp8_e4m3fn.safetensors
- 960×544
- 113フレーム
- 25steps
- embedded_guidance_scale: 6.0
- flow_shift: 9.0
- scheduler: FlowMatchDiscreteScheduler
- attention_mode: sageattn_varlen
- Torch Compile: 有効
- TeaCache: 0.15
- 生成時間(1動画あたり): 約6分20秒
seedは 777, 888, 999, 101010 の順です。
次に解像度を1280×720に上げます。
- 1280×720
- 97フレーム
- 25steps
- TeaCache: 無効 ※VRAM節約のため
- 生成時間(1動画あたり): 約21分32秒
Skyreels V1モデル
SkyReels V1のモデルに変更して同様に生成。
- model: skyreels_hunyuan_t2v_fp8_e4m3fn.safetensors
- 960×544
- 97フレーム
- 30steps
- embedded_guidance_scale: 1.0
- flow_shift: 9.0
- scheduler: SDE-DPMSolverMultistepScheduler
- attention_mode: sageattn_varlen
- Torch Compile: 有効
- TeaCache: 0.15
- 生成時間(1動画あたり): 約10分47秒
SDE-DPMSolverMultistepScheduler を使ったことで生成時間が長くなっています。
- 1280×720
- 97フレーム
- 30steps
- TeaCache: 無効
- 生成時間(1動画あたり): 約26分03秒
感想
2つのモデルで生成した感想は
- HunyuanVideoモデル
- 元の画像の雰囲気やプロンプトに忠実
8k photolialistic renderingと指定しても少しアニメーションっぽい感じになる
- Skyreelsモデル
- 映画の1シーンのようなリアルな映像を生成できるが、人の顔や手がうまく描けていないことが多い
- 元の画像の雰囲気やプロンプトにはあまり忠実ではない
- SDE-DPMSolverMultistepSchedulerを使うので生成時間が長くなる
あと、1280×720の動画をVRAM16GBで生成するのは少し厳しいと感じました。RTX4090かRTX5090が欲しい。


コメント