
kijai氏のComfyUI-HunyuanVideoWrapperでの動画生成で、生成時間に関わる部分を比較しました。
最終的には432×768, 97frames を1動画あたり41秒で生成できました。※ロード時間等は含まず
前置き
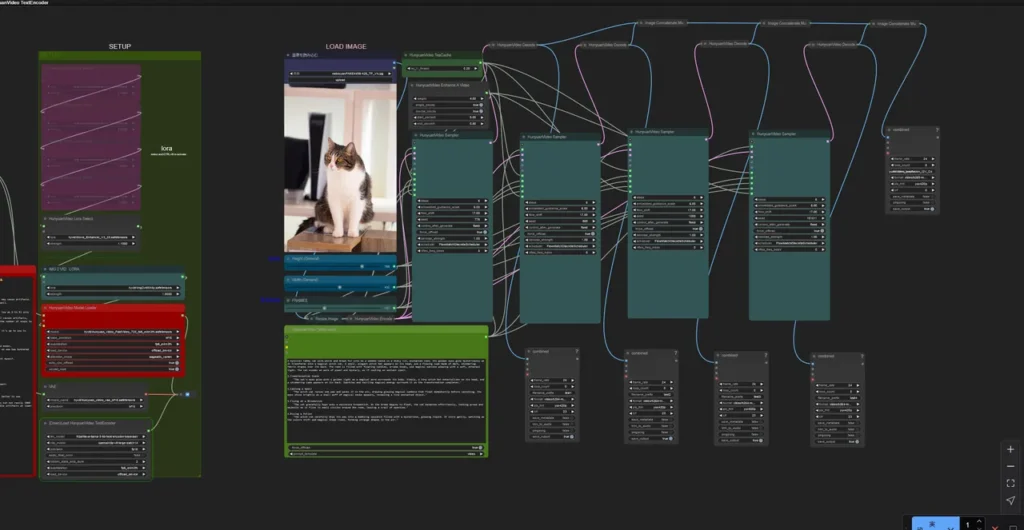
使用モデル
6stepsで動画を生成できるモデルを使いました。

ワークフロー
実行環境
- Windows 11
- Nvidia RTX 4080 16GB
- ComfyUI_portable
ComfyUIやtritonその他インストールについては以前の記事を参考にしてください。

Torch Compile による最適化
HunyuanVideo Torch Compile Settings ノード
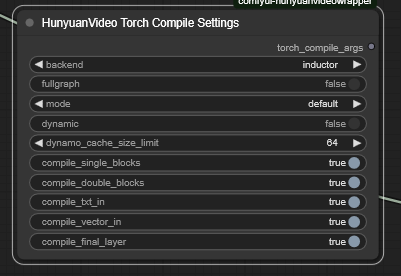
このノードをHunyuanVideo Model Loader ノードに接続するとtorch.compile() によるJITコンパイルが行われ、PyTorchのコードがカーネルに最適化されるそうです。
使うには triton のインストールが必要です。未インストールの方は以前の記事を参考にしてください。
Torch Compileによる最適化の検証
- 432xx768
- 121フレーム
- 6steps
HunyuanVideo Torch Compile Settings ノードありの場合となしの場合でワークフローを2回実行し、それぞれの実行時間と動画生成中のVRAM使用量を比較します。
ワークフローは1回の実行で4つの動画を生成するものを使いました。
Torch Compile なしの場合:
| 実行回数 | VRAM使用量 | ワークフロー実行時間 | 動画1 | 動画2 | 動画3 | 動画4 |
|---|---|---|---|---|---|---|
| 1回目 | 13.2GB | 7m26s | 1m11s | 1m11s | 1m09s | 1m09s |
| 2回目 | 12.9GB | 6m50s | 1m10s | 1m10s | 1m10s | 1m10s |
Torch Compile ありの場合:
| 実行回数 | VRAM使用量 | ワークフロー実行時間 | 動画1 | 動画2 | 動画3 | 動画4 |
|---|---|---|---|---|---|---|
| 1回目 | 10.9GB | 7m34s | 1m53s | 55s | 55s | 55s |
| 2回目 | 10.7GB | 5m50s | 59s | 55s | 55s | 55s |
HunyuanVideo Torch Compile Settings ノードをつなぐと特に2回目以降の生成時間が大幅に短縮されます。
1動画あたりでは 1m10s -> 55s なので、約21% の短縮です。
さらにVRAM使用量も減少するため、生成フレーム数を増やすこともできますね。
補足:コンパイルキャッシュによるエラーの解決
Torchコンパイル時にエラーが出たので、解決方法をメモしておきます。
私はComfyUI_portableの環境を複数持っているのですが、他の環境で作成されたキャッシュのせいで
ImportError: DLL load failed while importing __triton_launcher: 指定されたモジュールが見つかりません。というエラーが出てしまいました。
小一時間悩みましたが、以下のフォルダを削除することで解決しました。
C:\Users\<ユーザー名>\.triton
C:\Users\<ユーザー名>\AppData\Local\Temp\torchinductor_<ユーザー名>run_nvidia_gpu.bat を編集し、起動時に毎回キャッシュを削除するようにしました。
rmdir /s "%temp%\torchinductor_%username%"
rmdir /s "%HOMEDRIVE%%HOMEPATH%\.triton"
.\python_embeded\python.exe -s ComfyUI\main.py --windows-standalone-build
pauseattention_mode の比較
HunyuanVideo Model Loader ノード
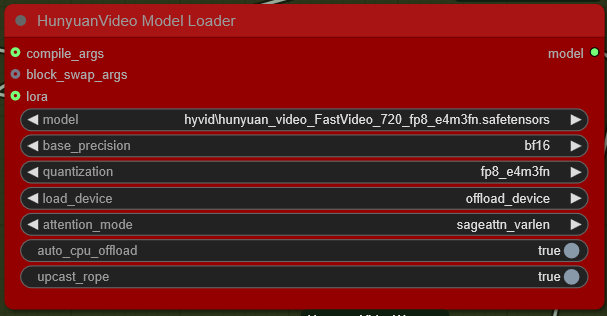
attention_modeは
- sdpa
- flash_attn_varlen
- sageattn_varlen
- sageattn
- comfy
を選ぶことができます。
各 attention_mode の生成速度を比較
各 attention_mode で実行し、生成時間とVRAM使用量を比較します。
| attention_mode | sdpa | flash_attn_varlen | sageattn_varlen | sageattn | comfy |
|---|---|---|---|---|---|
| 生成時間 | 2m20s | 1m16s | 55s | 50s | 2m12s |
| VRAM | 14.1GB | 11.0GB | 10.7GB | 12.1GB | 14.1GB |
sageattn_varlen が良さそうです。sdpa と比較すると 2m20s -> 55s と約61%も生成時間が削減され、VRAM使用量も少ないです。
sageattn も速いですが、sageattn_varlen と比較するとVRAM使用量が少し増えるようです。
なお、sageattn_varlenで実行するにはSageAttentionのインストールが必要です。未インストールの方は以前の記事を参考にしてください。
TeaCache
HunyuanVideo TeaCache ノード
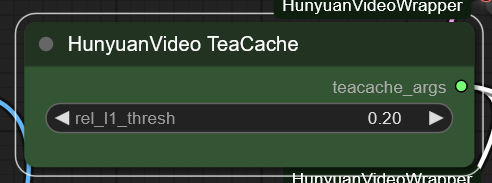
この数値を上げるほど生成が速くなるらしい。
TeaCache による高速化の検証
こちらも単一ワークフローで動画を2つ生成し、2つ目の動画の生成時間とVRAM使用量を比較しました。
| rel_l1_thresh | なし | 0.1 | 0.2 | 0.4 |
|---|---|---|---|---|
| 生成時間 | 1m21s | 1m20s | 53s | 53s |
| VRAM | 8.6GB | 10.9GB | 10.9GB | 11.0GB |
使うだけで2.3GBのVRAM使用量が増えました。
なしの場合と rel_l1_thresh=0.2 の場合を比較すると、 1m21s -> 53s と 約35% も生成時間が削減されました。
ただし、値を上げすぎると生成動画の品質が下がります(映像がぼやける感じ)。
デフォルト値の rel_l1_thresh=0.15 が品質と生成速度のバランスが良さそうです。
まとめ
- Torch Compile Settings ノードを使うと生成時間が短縮され、VRAM使用量も減少する
- attention_mode は sageattn_varlen が高速で省VRAMなのでおすすめ
- TeaCache ノードは rel_l1_thresh=0.15 くらいで使うと大幅に高速化され品質の低下も少ない。ただし、使うとVRAM使用量が増えることに注意。
最後に
最後に、一番遅い設定と速い設定でどれくらいの差があるかを比較
- 432×768
- 97フレーム
- 6steps
| 設定 | Torch Compile | attention_mode | TeaCache | VRAM使用量 | 生成時間 |
|---|---|---|---|---|---|
| 遅い設定 | なし | sdpa | なし | 12.7GB | 2m38s |
| 速い設定 | あり | sageattn_varlen | 0.2 | 9.1GB | 41s |
2m38s -> 41s と 約84% の短縮となりました。
※生成時間:HunyuanVideo Samplerノードの実行にかかった時間を計測
※モデルのロードやコンパイル時間は含みません


コメント