本記事ではOpenWebUI+ローカルLLM+VOICEVOXで会話する環境をDockerでまとめて構築していきます。
参考記事:

はじめに
Open WebUIでは返答を音声で読んでくれる機能あります。
発話方法は2種類
- Web API (SpeechSynthesis)
- OpenAI TTS API
VOICEBOXもAPIを通して音声合成できるのですが、Open WebUIはその形式に対応していないので直接リクエストすることはできません。が、
OpenAI TTS APIのリクエストをVOICEVOX APIに変換するブリッジを作成してくれている方がいるそうです。

今回はこのブリッジを使わせてもらい、返答をVOICEVOXで再生する環境をDockerで構築していきます。
ローカルLLMを使うためにOllamaも含めてまとめて構築できるようにします。
環境
- OS: Windows 11
- GPU: NVIDIA RTX 4080 VRAM 16GB
必要なもの
- WSL2で動くDocker環境
- CUDA-Toolkit
WSL2, CUDA-Toolkit, Dockerのインストールに関しては前の記事を参考にしてください。

使用するイメージ
VOIVEVOX 音声合成エンジン

Ollama
Open WebUI

WSL2の設定
WSL2で立ち上げたサービスにWindows側から localhost でアクセスするために、.wslconfig に設定を追加します。ファイルの場所は C:\Users\ユーザー名\.wslconfig です。
[wsl2]
localhostForwarding=Trueサービスの構築と起動
フォルダ構成
openwebui_voicevox
├── docker-compose.yaml
└── openaitts-voicevox-bridge
├── Dockerfile
└── config.inidocker-compose.yml
今回は NVIDIA GPUを使う設定をしています。CUDA-Toolkitがインストールされている必要があります。
version: '3.8'
services:
ollama:
image: ollama/ollama:latest
container_name: ollama
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
volumes:
- ollama_data:/root/.ollama
ports:
- "11434:11434"
restart: unless-stopped
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
ports:
- "3000:8080"
environment:
- OLLAMA_BASE_URL=http://ollama:11434
depends_on:
- ollama
volumes:
- open-webui_data:/app/backend/data
restart: unless-stopped
voicevox-engine:
image: voicevox/voicevox_engine:cpu-latest
container_name: voicevox-engine
ports:
- "50021:50021"
restart: unless-stopped
openaitts-voicevox-bridge:
build:
context: .
dockerfile: ./openaitts-voicevox-bridge/Dockerfile
container_name: openaitts-voicevox-bridge
ports:
- "8000:8000"
depends_on:
- voicevox-engine
volumes:
- ./openaitts-voicevox-bridge/config.ini:/app/openaitts_voicevox_bridge/config.ini
restart: unless-stopped
volumes:
ollama_data:
open-webui_data:openaitts-voicevox-bridge/Dockerfile
参考記事からそのまま引用させてもらいました。
FROM python:3.12-slim-bullseye
# 必要なパッケージのインストール
RUN apt-get update && apt-get install -y \
ffmpeg \
git \
&& apt-get clean
# リポジトリのクローン
WORKDIR /app
RUN git clone https://github.com/NP-F/openaitts_voicevox_bridge /app/openaitts_voicevox_bridge
WORKDIR /app/openaitts_voicevox_bridge
# Python依存関係のインストール
RUN pip install --upgrade pip && pip install -r requirements.txt
# config.iniのコピー
COPY config.ini /app/openaitts_voicevox_bridge/config.ini
CMD ["python", "openaitts2voicevox_bridge.py"]openaitts-voicevox-bridge/config.ini
OpenAI TTS APIをVOICEVOX APIに変換する際の設定を書くファイルです。
OpenAI TTSの voice (ALLOY, ECHO…) とVOICEVOXの speaker_id(番号)を対応させます。
今回は以下のように設定しました。
| OpenAI TTS | VOICEVOX | キャラクター |
|---|---|---|
| ALLO | 2 | 四国めたん(ノーマル) |
| ECHO | 0 | 四国めたん(あまあま) |
| FABLE | 3 | ずんだもん(ノーマル) |
| ONYX | 1 | ずんだもん(あまあま) |
| NOVA | 14 | 冥鳴ひまり(ノーマル) |
| SHIMMER | 20 | もち子さん(ノーマル) |
| DEFAULT_SPEAKER | 2 |
[SETTINGS]
PARSERATE = 2
HOST = 0.0.0.0
PORT = 8000
[SOUND]
SAMPLING_RATE = 44100
BITDEPTH = 2
[VOICEVOX]
AUTOLAUNCH = false
PATH = /PATH/TO/VOICEVOX/EXECUTABLE
API = http://voicevox-engine:50021
[ALTID]
ALLOY = 2
ECHO = 0
FABLE = 3
ONYX = 1
NOVA = 14
SHIMMER = 20
DEFAULT_SPEAKER = 2コンテナの起動
docker compose up -dOpen WebUIの設定
ブラウザで http://localhost:3000 を開くとOpen WebUIの画面が表示されます。
初期設定などは前回の記事を参考にしてください。
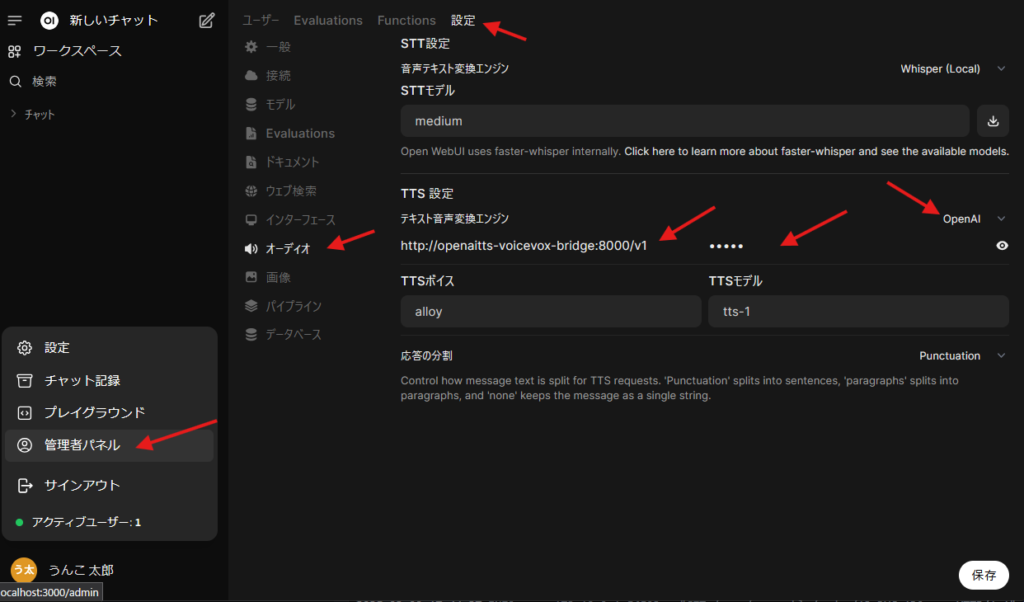
VOICEVOXで再生するために、管理者パネル > 設定 > オーディオ を開き、次の箇所を設定します。
- テキスト音声変換エンジン: OpenAI
- API ベース URL:
http://openaitts-voicevox-bridge:8000/v1 - API キー: 任意の文字列 (例:
test - 最後に忘れずに保存
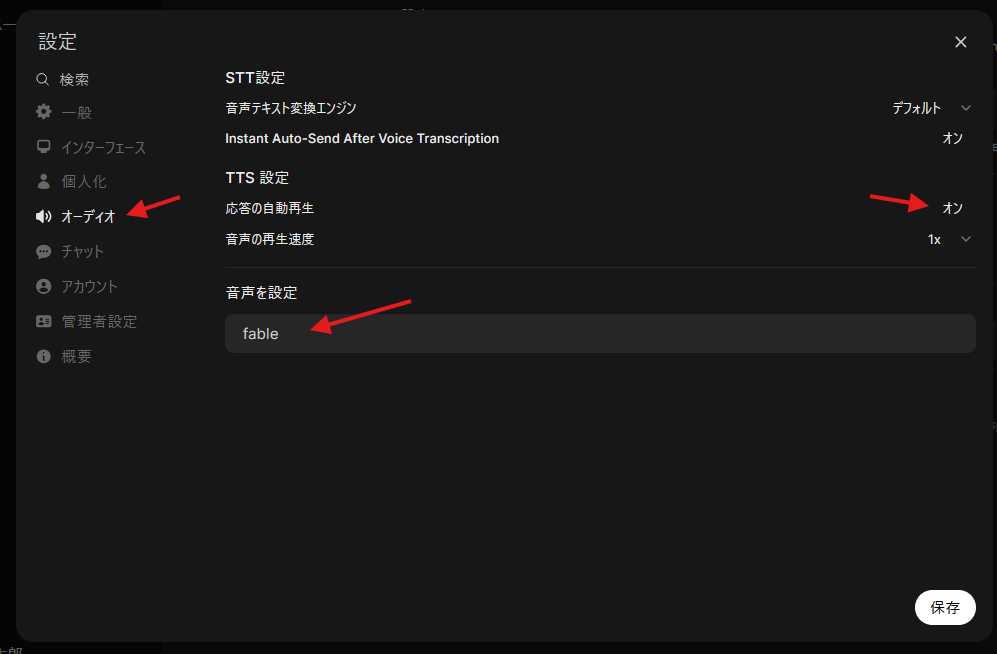
次に、応答を自動再生するために、設定 > オーディオ を開き、次の箇所を設定します。
- 応答の自動再生: オン
- 音声を設定: fable (ずんだもん)
- 忘れずに保存
チャットのテスト
Open WebUIの画面でチャットを送信すると、VOICEVOXで返答が再生されます。
VOICEVOX:ずんだもん
立ち絵:坂本アヒル 様
おわりに
Dockerを使うことで比較的簡単に構築できました。
今回はGPUを使ってローカルLLMを動かしましたが、Open WebUIではAPI経由でGPT-4oなどの高性能なモデルを使うこともできます。


コメント